웹 크롤링하기 - 실검 1위 가져오기 (bs4 - BeautifulSoup)
인터넷 사이트에서 원하는 정보를 가져와보도록 합시다.
-
필요한 재료 설치
웹 크롤링을 진행할 때 requests와 beautifulsoup4를 활용할 것이므로 없다면 깔아주도록 합시다.
명령프롬프트 (or cmd창)을 열어 requests와 beautifulsoup4를 설치합니다.
> pip install requests> pip install beautifulsoup4
-
설치한 requests, beautifulsoup4 불러오기
이제 코드 작성을 시작해봅시다.
설치한 requests와 beautifulsoup4를 사용할 것이므로 먼저 불러와주도록 합시다.
import requests
from bs4 import BeautifulSoup
-
url저장 - 원하는 정보가 있는 페이지의 주소를 복사
저는 다음의 실시간 검색어 1위를 받아오는 코드를 적을 것입니다.
url이라는 변수를 만들어 그곳에 다음의 주소를 문자열 형태로 저장해봅시다.
url = 'https://www.daum.net/'현재까지 코드
import requests
from bs4 import BeautifulSoup
url = 'https://www.daum.net/'
-
원본 텍스트 가져오기
위의 url을 가져왔던 페이지에서 원본 텍스트를 가져와야 합니다.
이때 requests 모듈을 사용합니다. (파이썬을 사용하여 HTTP요청을 보내는 모듈입니다.)
다음 코드를 입력 해봅시다.
response = requests.get(url).text이때 .text를 사용하여 url에서 가져온 정보 중에 텍스트만 가져옵니다.
현재까지 코드
import requests
from bs4 import BeautifulSoup
url = 'https://www.daum.net/'
response = requests.get(url).text
-
텍스트 다듬기 (Beautifulsoup 사용)
원본 텍스트는 가져왔지만 지저분할 겁니다.
이것처럼 말이죠

텍스트를 다듬기 위해 다음과 같은 코드를 작성합니다.
data = BeautifulSoup(response, 'html.parser')이때 'html.parser'를 넣어주는 이유는 가져온 데이터가 html형식이기 때문입니다.
위의 코드를 작성한 후엔 data에 원본 데이터가 분류되어 저장됩니다.
이제 이 중에 원하는 부분을 선택해야 합니다.
현재까지 코드
import requests
from bs4 import BeautifulSoup
url = 'https://www.daum.net/'
response = requests.get(url).text
data = BeautifulSoup(response, 'html.parser')
-
다듬은 텍스트 중 원하는 부분 가져오기 (selector)
다듬은 텍스트에서 원하는 부분을 가져올 때, selector라는 부분을 복사해서 가져옵니다.
저는 다음에서 데이터를 가져왔기 때문에, 다음으로 접속해서 개발자 도구(F12)를 열어줍니다.
다음에서 개발자 도구를 연다

그러면 우측에 파랗게 된 부분이 있습니다.
그 위에서 오른쪽 마우스를 클릭하여 copy selector를 선택하여 셀렉터를 복사합니다.
copy selector
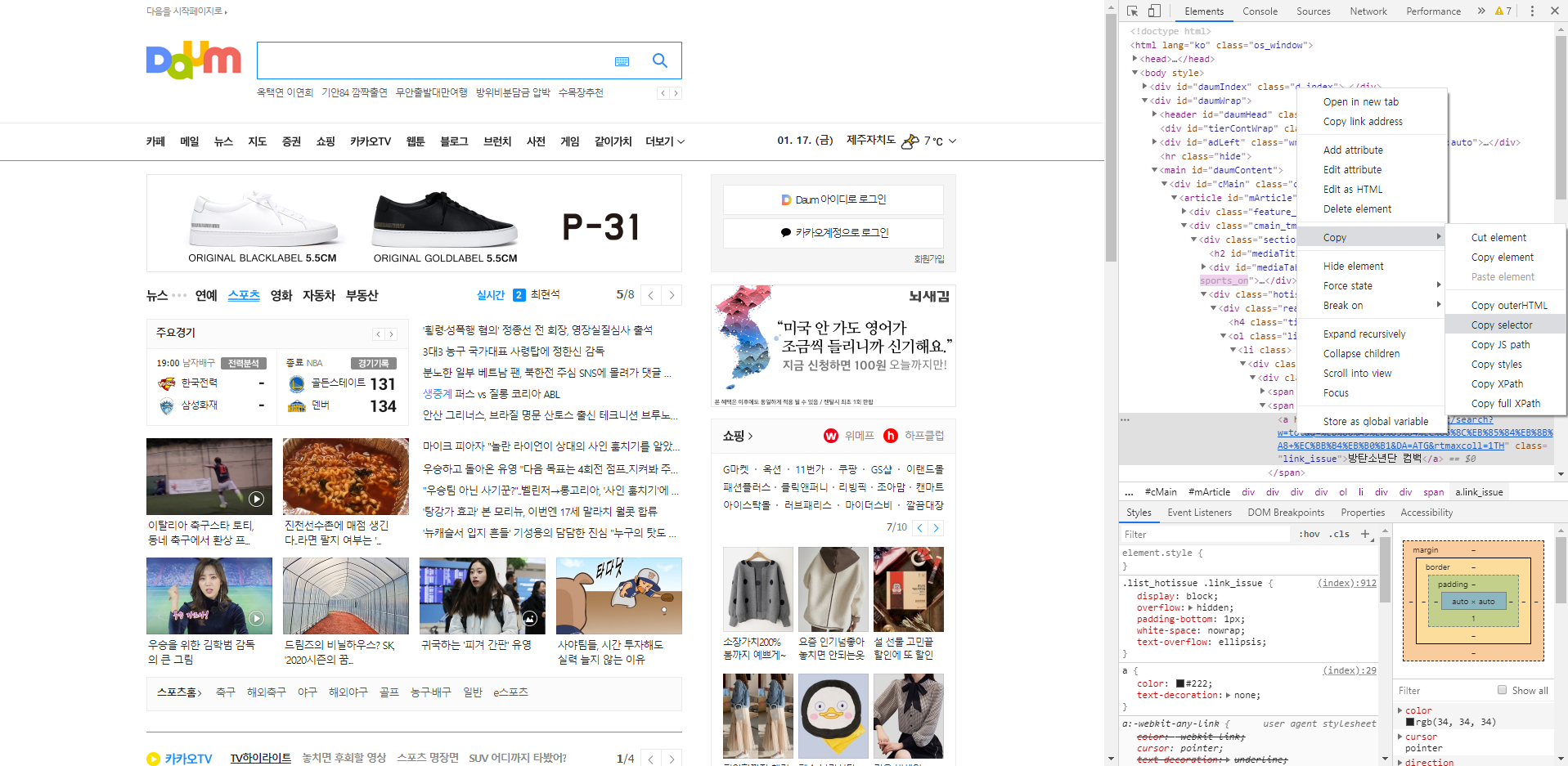
이제 다음과 같은 코드를 입력합니다.
search = data.select_one('').text여기 작은 따옴표 안에 복사한 selector를 붙여넣습니다. 저는 다음과 같이 됐습니다.
search = data.select_one('#mArticle > div.cmain_tmp > div.section_media > div.hot_issue.issue_mini > div.hotissue_mini > ol > li:nth-child(1) > div > div > span.txt_issue > a').text.select_one을 사용하여 선택한 셀렉터에 해당하는 부분만 가져왔고,
.text를 사용하여 그 부분의 텍스트만 가져왔습니다.
현재까지 코드
import requests
from bs4 import BeautifulSoup
url = 'https://www.daum.net/'
response = requests.get(url).text
data = BeautifulSoup(response, 'html.parser')
search = data.select_one('#mArticle > div.cmain_tmp > div.section_media > div.hot_issue.issue_mini > div.hotissue_mini > ol > li:nth-child(1) > div > div > span.txt_issue > a').text
-
끝
다 됐습니다!
이제 프린트를 하든 이후에 웹페이지에서 띄워주든 원하는 대로 할 수 있습니다.
저는 간단하게 명령 창에 띄워보기만 하겠습니다.
print(search)
결과

이것으로 인터넷에서 크롤링하기를 완료했습니다.
전체 코드
import requests
from bs4 import BeautifulSoup
url = 'https://www.daum.net/'
response = requests.get(url).text
data = BeautifulSoup(response, 'html.parser')
search = data.select_one('#mArticle > div.cmain_tmp > div.section_media > div.hot_issue.issue_mini > div.hotissue_mini > ol > li:nth-child(1) > div > div > span.txt_issue > a').text
print(search)